This was a small project I wrote to learn about writing concurrent programs and networking in C++. In this blog, I'll be writing about the things I leaned and the process of building the web server.
At its core, a web server is simply a server that accepts incoming HTTP requests, and serves a HTTP response. For my web server, I kept it simple - for every GET request, it would just respond with a HTML file.

A single-threaded server has its limits. With only one thread accepting and handling requests, throughput is greatly constrained to how much the single worker thread can handle at once, and this varies depending on the amount of processing needed for the request, response payload, etc.
Here are the benchmarks for my initial single-threaded web server - simply the main thread accepting and responding to requests in a while loop.
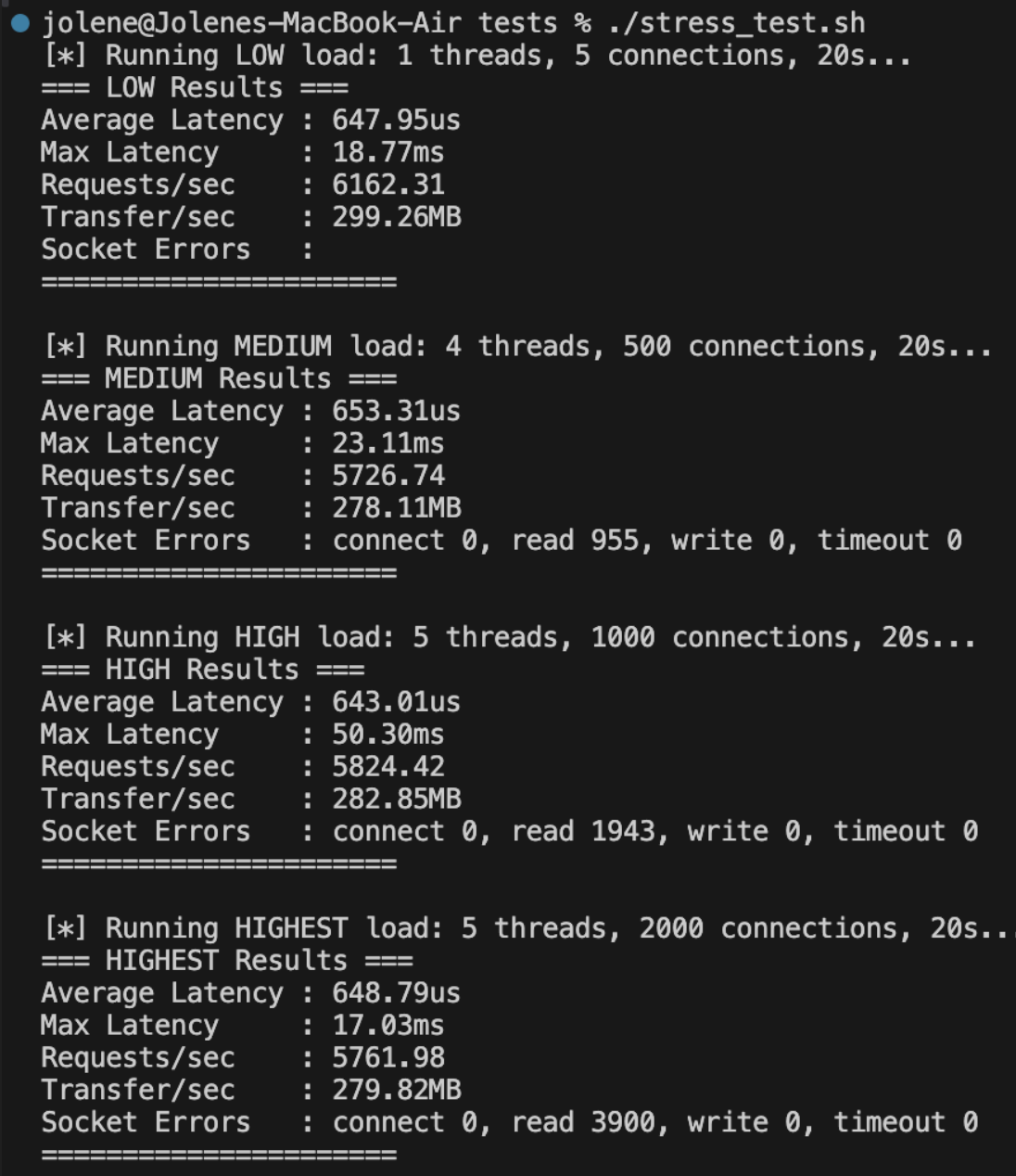 Our current throughput (requests/sec) averages 5869 requests/sec across all loads. It sounds okay but as we'll see later on, it can get better.
Our current throughput (requests/sec) averages 5869 requests/sec across all loads. It sounds okay but as we'll see later on, it can get better.
There are many ways one can design a web server, as detailed in the table below.
| Architecture | Description | Examples |
|---|---|---|
| Event-driven (asynchronous I/O) | Uses non-blocking I/O and a single event loop; scales efficiently with many concurrent connections | Nginx, Node.js |
| Thread-per-request | Spawns a new thread for every client connection | older Apache model, educational servers |
| Thread-pool / worker model | Fixed number of threads process queued connections; avoids thread creation overhead | modern Apache (worker mode), Java executors |
| Hybrid / async + thread pool | Combines async I/O with worker threads for CPU-bound tasks | Go net/http, Rust’s tokio + thread pool |
Event-driven architecture is also an interesting one, but for now I chose to implement a thread-pool model because I wanted to try out multi-threading and designing thread-safe data structures.
[!info] Event-Driven Architecture
- Event-Driven web servers have a single thread that runs an event loop. The event loop listens for events from a particular connection socket / listening socket, and responds correspondingly.
- The event loop waits for event notifications from the OS and sleeps if there are no events currently. It does this via the
epoll_wait()system call (Linux).- When a request connection comes in, the kernel detects activity in the listening socket, and wakes up the event loop to handle it.
- The event loop accepts the connection, creates a new connection socket for that request, then submits that connection socket to the OS.
- Whenever a socket has activity (eg. is ready to be read from/written to), the OS informs the event loop, which wakes up and handles it correspondingly.
- This allows the single-threaded event loop to handle multiple requests concurrently by interleaving the process of handling each connection.
- Why this works: most of the time, handling a request involves a lot of I/O in which the handling thread stays idle.
epoll_wait()allows us to respond to a socket only when needed. This way, CPU time is not wasted waiting for I/O, and the handler thread can serve other active requests in the meantime.
As mentioned above, this was the model I chose to implement because I wanted to try writing multi-threaded programs and thread-safe data structures. Below is the architecture diagram for this model:
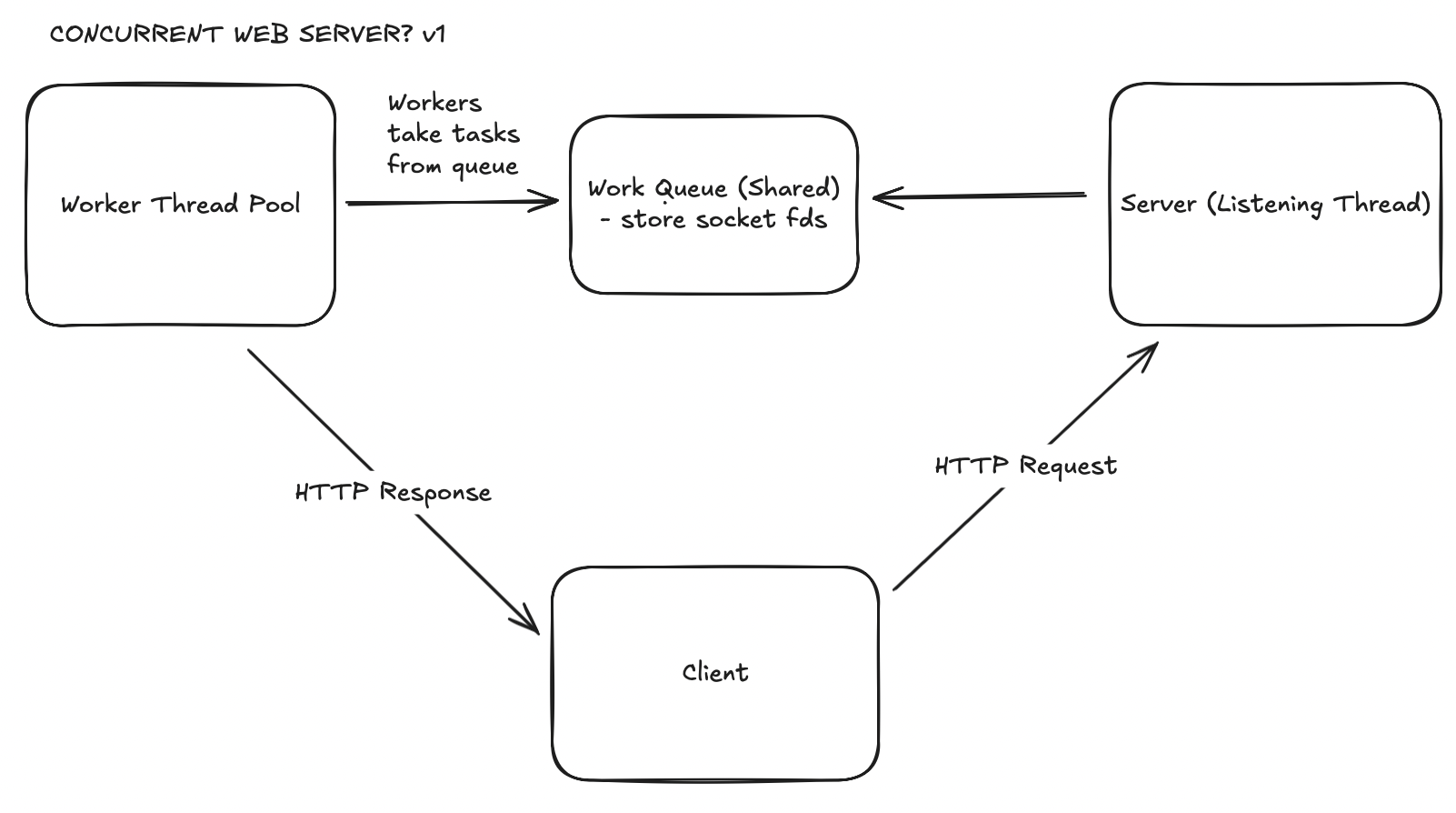
accepts() it, which creates a new connection socket.front points to the head node of the queue, back points to the tail node of the queue.
null.front to point to the same node as back, wee need to be careful in push() and pop() where we'll be modifying these.size == capacity.push - pushes an element to the back of the queue
back to point to this elementfront to point to this element as wellwait_and_push() - thread goes to sleep if the queue is full; wakes up and pushes once notifiedpop - pops from the back of the queue.
front to point to the next element, or null if nonequeue initially had one element and is now empty, update back to nullwait_and_pop() - thread goes to sleep if the queue is empty; wakes up and pops once notifiedtemplate <typename T> class JobQueue { public: JobQueue(int capacity) : m_capacity{capacity}, m_size{0}, m_front{nullptr}, m_back{nullptr} {}; // non-blocking - once a push fails, the caller is responsible for calling and trying again void push(T item) { std::lock_guard<std::mutex> lock(m_mut); if (m_size == m_capacity) { throw JobQueueFullException("Job queue full"); } Node<T> *newNode = new Node<T>(item); if (this->empty()) { m_front = newNode; m_back = newNode; // need to look front and back } else { m_back->next = newNode; m_back = newNode; } m_size++; }; // waits until we are not full before pushing. void wait_and_push(const T &item) { std::unique_lock<std::mutex> lock(m_mut); m_not_full.wait(lock, [this] { return !this->full(); }); Node<T> *newNode = new Node<T>(item); if (this->empty()) { m_front = newNode; m_back = newNode; // need to lock front and back } else { m_back->next = newNode; m_back = newNode; } m_size++; // unlock before notifying consumers // this is an optional optimization - ensures that // once waiting threads are awoken, they will immediately have access to the mutex // withiout having to wait for this function to return and for the unique_lock to go out of scope. lock.unlock(); m_not_empty.notify_one(); } T pop() { std::lock_guard<std::mutex> lock(m_mut); if (this->empty()) { throw JobQueueEmptyException("Job queue empty"); } Node<T> *oldHead = m_front; // this needds to be locked, but back also needs to be locked cause both could be the same T val = oldHead->value; m_size--; if (m_size == 0) { m_front = nullptr; m_back = nullptr; } else { m_front = oldHead->next; } delete oldHead; return val; }; // blocks if queue is empty, wakes it up once something has been added to queue T wait_and_pop() { // lock the mutex, and pass lock to cv std::unique_lock<std::mutex> lock(m_mut); m_not_empty.wait(lock, [this] { return !this->empty(); }); Node<T> *oldHead = m_front; // this needds to be locked, but back also needsto be locked cause both could be the same T val = oldHead->value; m_size--; if (m_size == 0) { m_front = nullptr; m_back = nullptr; } else { m_front = oldHead->next; } delete oldHead; // unlock mutex, and notify producer threads that we are now not full lock.unlock(); m_not_full.notify_one(); return val; }
The screenshots are in the project's README. I didn't include it here because I don't want this blog to become bloated. Here is a summary comparing the performance of my web server across different configurations:
| Worker Threads | Queue Capacity | Avg Latency (µs/ms) | Req/s | Throughput (MB/s) | Observations |
|---|---|---|---|---|---|
| Naive (no sync) | No queue | ~0.64 ms (LOW) → ~0.65 ms (HIGHEST) | ~5 700–6 100 | ~280–300 MB/s | Baseline unsynchronised server; moderate throughput but unsafe under concurrency |
| 1 | 100 | ~0.99 ms (LOW) → ~19 ms (HIGHEST) | ~5 200 | ~254 MB/s | Baseline single-threaded (sequential) |
| 3 | 100 | ~0.6 ms (LOW) → ~8 ms (HIGHEST) | ~11 000 | ~540 MB/s | Big jump in throughput; latency cut in half |
| 10 | 100 | ~0.42–0.53 ms (LOWEST) | ~11 000–13 000 | ~530–650 MB/s | Peak throughput; lowest latency |
| 20 | 100 | ~0.6–0.9 ms | ~8 600–9 600 | ~420–460 MB/s | Throughput drops again; diminishing returns |
From the results, it's clear how having too little threads to service requests leads to high latency, but having too many past a certain point leads to diminishing returns as high contention for a bounded queue leads to greater overhead. It shows how tweaking parameters are just as important as the system's design.
Latency aside, we see how throughput is much higher with multiple threads handling our workload - it improves by a factor of 2 (at 10 worker threads)!
pop() from the queue, and if an exception threw, they would sleep for one second before trying again. This led to increased latency as some requests would have to wait for worker threads to wake up and pop it. When I had worker threads wait on a condition variable instead, they got woken up the moment the queue wasn't empty, and this improved the average latency per request.n threads in the pool, we can only serve n requests at once. Other requests will have to wait in the queue, leading to higher latency and lower responsiveness especially if each request takes significant time to complete. (Eg. high I/O time).